Amélioration de l’algorithme de recherche
La lenteur et le peu de ressources internes du 68705 limitaient les performances de la recherche.
? Déjà rien qu’en portant le nombre de prélèvements par ligne à 16 au lieu de 4, soit un toutes les ?3µs, on quadruple le nombre de piles d’échantillons et on multiplie d’autant les espérances de succès .
? N’étant plus limité par la mémoire interne, on peut stocker les prélèvements d’une trame entière qu’il faudra cependant restreindre d’une cinquantaine de lignes en haut et en bas de l’image pour cause de bandes noires inhérentes aux films en cinémascope. On arrive ainsi à pratiquement doubler la hauteur des piles d’échantillons (sur 186 lignes au lieu de 94).
? En considérant à la fois les augmentations et les diminutions d’intensité, on double encore les chances de capturer des variations de luminosité dans l’image.
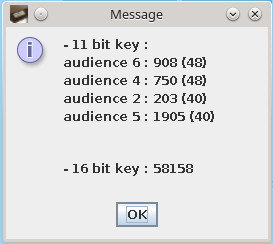
Avec de telles retouches, les espérances de succès se retrouveraient multipliées par 16, le hic c’est que le taux d’erreurs (?3%) reste le même si l’on se contente toujours de 18 échantillons consécutifs certifiés pour reconstituer le mot d’initialisation du GPA. Il en faudrait pas moins de 54 pour garantir un taux de réussite de 100% selon la feuille LibreOffice du précédent message.
Il va donc falloir rechercher, parmi toutes les piles de 186 échantillons, une série de 54 échantillons consécutifs certifiés pour atteindre cet objectif. Une image quelconque ne comportant pas nécessairement une zone quasi verticale de variation de luminosité d’une telle hauteur, à défaut, il va donc falloir se contenter de la série qui possèdera le meilleur score, en tout cas supérieur à 18, pour maximiser le taux de réussite.
Le classeur LibreOffice ci-dessous simule ce nouvel algorithme de recherche sur une seule pile d’échantillons. Dans la réalité la recherche devra se faire sur autant de piles que de prélèvements effectués à intervalles réguliers dans les 52µs actives de chaque ligne de la 1ère trame du cycle.
Recherche.New.ods.TXT (236 KB)
Ce classeur comporte 6 feuilles, elles sont toutes protégées sans mot de passe.
? La feuille « GPA »: Colonnes D à N, les itérations successives du GPA sur les 6 trames d’un cycle. En colonne O, le retard associé.
Le mot d’initialisation peut être modifié bit par bit: double-cliquer dans une des cellules D2 à N2 pour inverser à chaque fois l’état du bit correspondant.
? La feuille « Echantillons »: Colonnes D, E, F et G: Simulation des échantillons prélevés respectivement aux instants B, C, F et G selon le diagramme en tête des colonnes.
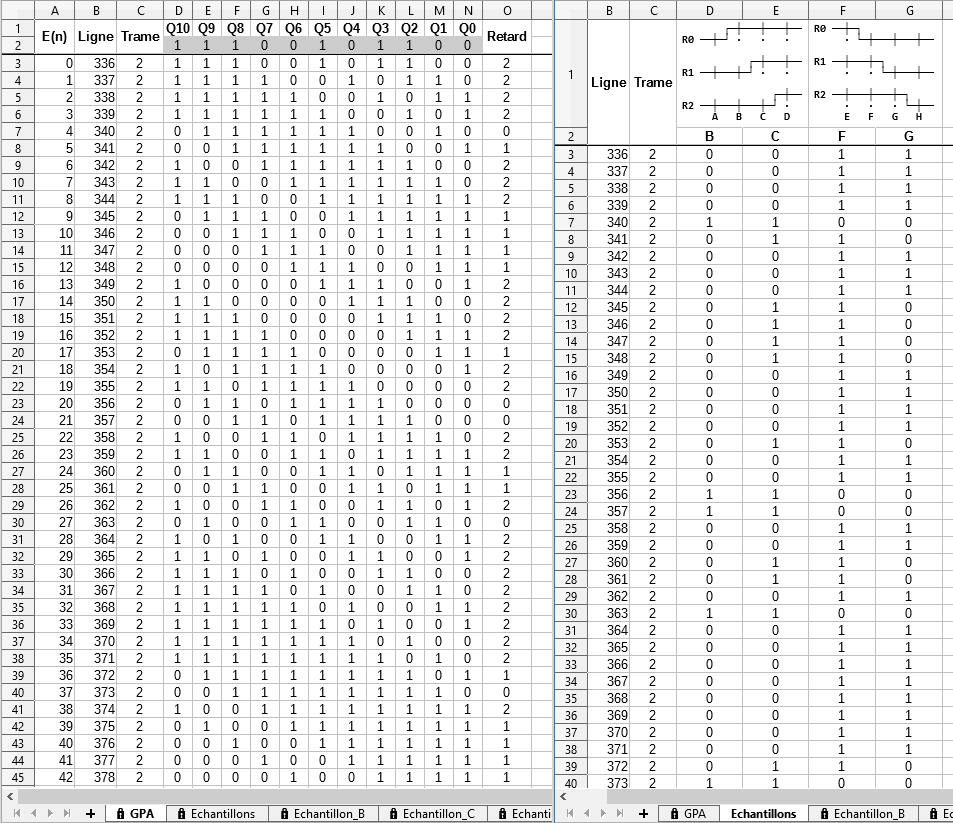
? Les feuilles « Echantillon_X »: Une feuille dédiée à la recherche pour chaque instant de prélèvement B, C, F ou G dans sa pile d’échantillons respective.
? Colonne D: les échantillons, les 50 premiers et 50 derniers de la trame sont ignorés. Pour créer des erreurs, chaque échantillon peut être inversé individuellement en double-cliquant dans la cellule associée, pour ce faire, la protection de la feuille doit provisoirement être inhibée. La couleur du fond de la cellule vire alors au rouge ou redevient neutre pour signaler s’il y a inversion ou pas,
? Colonne E: le résultat du XOR entre le 2ème et le 11ème échantillon après l’échantillon courant.
? Colonne F: le résultat de la comparaison entre le résultat du XOR et l’échantillon courant. (0 si « ? », 1 si « = »).
? Colonne G: comptabilisation des exactitudes et des inexactitudes consécutives. Afin de les distinguer, les premières sont comptées positivement et les secondes négativement. Le compte est réinitialisé à ±1 quand le résultat de la comparaison est inverse du précédent.
? Colonnes J à T: reconstitution des itérations à rebours du GPA jusqu’à la première ligne active (336) de la trame.
? Cellule G1: meilleur score sur les inexactitudes consécutives, négatif, ce score correspond à une augmentation de luminosité dans l’image.
? Cellule G2: meilleur score sur les exactitudes consécutives, il correspondent à une diminution de luminosité.
? Cellule H2: meilleur score des deux en valeur absolue, il est nul s’ils sont égaux.
? Cellule I2: numéro de la ligne où le contenu du GPA reconstitué devra être inséré, vaut celui de la 10éme ligne après celle affichant le meilleur score. Ce numéro est nul pour un score inférieur à 18.
? Cellules J2 à T2:: reconstitution du contenu du GPA à partir des 11 derniers échantillons appartenant au meilleur score. L’état des échantillons, donc celui des bits, est complémenté si ce score est négatif. Le contenu est vide si le score est inférieur à 18.
? Ligne pointée par la cellule I2: C’est la destinataire du contenu du GPA reconstitué dans les cellules J2 à T2 .
? Lignes en dessous de cette ligne: Le contenu des lignes suivantes demeure vide car il est indéterminé.
? Lignes au dessus de cette ligne: Le contenu est itéré à rebours pour toutes celles qui la précède jusqu’à la première ligne de la trame (la 336). Sur cette dernière ligne, on obtient finalement le mot clef qui a initialisé le GPA en début de cycle (cellules à couleur de fond jaune).
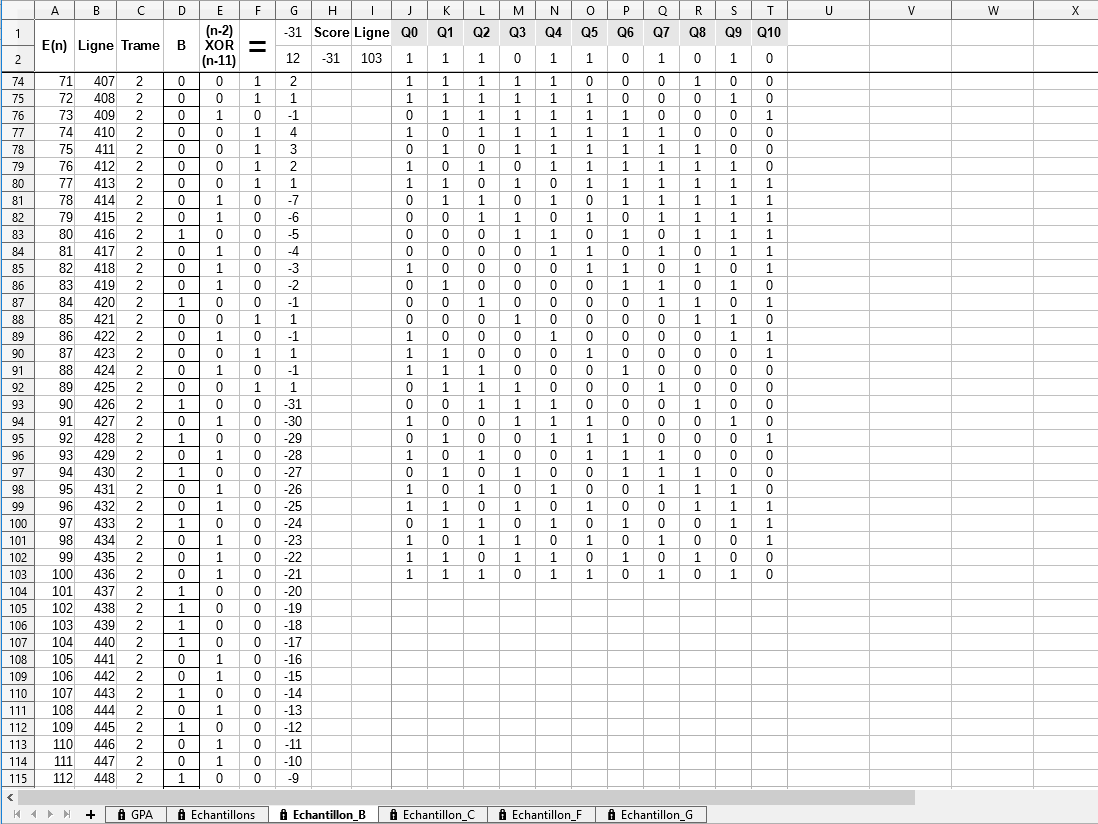
Sur cette feuille concernant une pile d’échantillons prélevés à l’instant « B » et avec le GPA initialisé à 072CH (111.0010.1100B) au départ, on obtient un score de 31, ce qui fausserait le résultat s’il était pris en compte. Il est donc impératif de réaliser un nombre conséquent de prélèvements à intervalles réguliers dans les lignes afin d’espérer trouver un score bien meilleur qui proviendrait d’une configuration telle que celles des instants « C » ou « G ». L’idéal serait qu’il soit supérieur ou égal à 54 pour obtenir 100% de réussite car on aurait alors la certitude absolue que les échantillons considérés sont assimilables à cet instant au contenu du GPA.
 Doctsf (Modèles & Marques)
Doctsf (Modèles & Marques) Annonces
Annonces [TDA4565]
[TDA4565]